


需求来源
最近跑步减肥,边跑边听歌,但是不想带手机跑,于是找到一款可以离线导入mp3文件到apple watch的应用:One Player,非常好用,甚至作为一款ios端的离线听歌软件也是挺好的,强烈推荐。
但是有一个问题,就是网上下载的mp3音乐虽然文件名是正确的,但是导入到One Player里后标题和歌手名称偶尔会出现有乱码的现象。
解决方案
当然One Player里就有现成的功能可以解决这个问题,就是编辑歌曲信息中有编辑歌名、编辑艺人、编辑专辑,可以分别修改mp3文件对应的歌曲元数据信息,修改好了后列表就能正常显示了。
但是我这次导入的歌曲有几十首,难道我得一个个点击修改,然后网上查询对应的信息然后手动修改天上吗?这也太麻烦了,于是想到可不可以写段代码批量修改歌曲的元数据信息,改好后再批量导入到One Player不就可以了。
修改mp3元数据信息,刚好python有现成的第三方依赖库可以实现,我去deepseek问问就给我生成了代码改改就能用,主要问题是如何根据歌名获取到歌曲的元数据信息,包括完整歌名、歌手名称、专辑名称,这里我尝试找第三方的接口,但是好像并没有现成的接口可以用。既然没有接口我就试试让AI给我回复元数据信息吧,参考deepseek的开发文档:https://api-docs.deepseek.com/zh-cn/
写了一段ai提示词:
作为音乐元数据查询助手,请根据用户提供的歌曲名称返回以下3行标准化信息:
第一行:歌曲名称(用户输入的原名或最匹配的官方名称)
第二行:歌手/艺术家(主艺人,多个艺人时用'&'连接)
第三行:所属专辑(最匹配的官方专辑名称),专辑不要添加书名号
若无法确认信息,相应行返回'未知'。无需额外解释,直接输出3行结果。
示例输入:
'晴天'
示例输出:
晴天
周杰伦
叶惠美
现在请处理用户查询:
使用该提示词对ai提问输入歌名,即可输出歌曲的这三个元数据信息,提示词的编写技巧也可以参考deepseek的文档。
代码分享
既然核心问题都解决了,于是编写了以下代码:
import os
from mutagen.easyid3 import EasyID3
from mutagen.mp3 import MP3
from openai import OpenAI
client = OpenAI(api_key="sk-xxxxxxxxxxxxxxx", base_url="https://api.deepseek.com")
# 查询元数据信息
def search_music_by_title(song_name):
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": '''
作为音乐元数据查询助手,请根据用户提供的歌曲名称返回以下3行标准化信息:
第一行:歌曲名称(用户输入的原名或最匹配的官方名称)
第二行:歌手/艺术家(主艺人,多个艺人时用'&'连接)
第三行:所属专辑(最匹配的官方专辑名称),专辑不要添加书名号
若无法确认信息,相应行返回'未知'。无需额外解释,直接输出3行结果。
示例输入:
'晴天'
示例输出:
晴天
周杰伦
叶惠美
现在请处理用户查询:
'''},
{"role": "user", "content": song_name},
],
stream=False
)
result = response.choices[0].message.content.split('\n')
print(f"识别到歌曲【'{song_name}'】的元数据信息:{result}")
return result
# 读取元数据信息
def read_metadata(file_path):
try:
audio = EasyID3(file_path)
print(audio["title"])
print(audio["artist"])
print(audio["album"])
except:
print(f"❌ 读取元数据失败: {os.path.basename(file_path)} \n")
# 写入元数据
def write_metadata(file_path, metadata):
try:
try:
audio = EasyID3(file_path)
except Exception:
audio = MP3(file_path)
audio.add_tags()
audio = EasyID3(file_path)
audio["title"] = metadata[0]
audio["artist"] = metadata[1]
audio["album"] = metadata[2]
audio.save()
print(f"✅ 已更新元数据: {os.path.basename(file_path)} \n")
except:
print(f"❌ 更新元数据失败: {os.path.basename(file_path)} \n")
# 主流程
def process_folder(folder):
for root, _, files in os.walk(folder):
for filename in files:
if filename.lower().endswith(".mp3"):
file_path = os.path.join(root, filename)
song_name = os.path.splitext(filename)[0] # 文件名去掉扩展名
print(f"🔍 识别: {song_name}")
info = search_music_by_title(song_name)
if info:
write_metadata(file_path, info)
else:
print(f"❌ 未找到信息: {song_name}")
# 使用你的 MP3 文件夹路径
music_folder = "/Users/chengpei/Music/Music/五月天"
process_folder(music_folder)
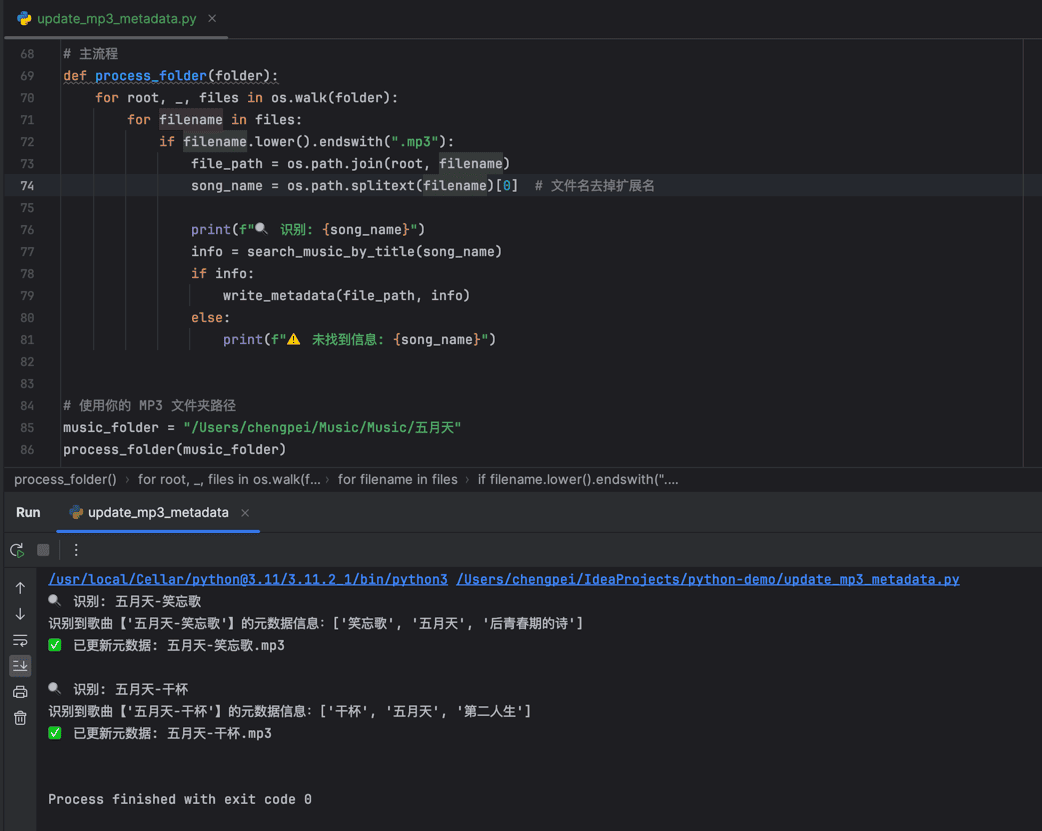
流程就是遍历指定的文件夹,获取mp3的文件名,然后输入文件名调用deepseek接口,其返回三行的元数据信息,再将其写入到mp3文件内即可,运行效果如下:
评论区